Everyone is Solving the Wrong Problem
The AI infrastructure discourse has a blind spot the size of a power grid.
Open any research blog right now. Distributed training. Decentralized inference. Cheaper GPUs. Faster interconnects. Mixture-of-Experts. Inference-time compute scaling. Asynchronous RL across heterogeneous swarms. These are real breakthroughs by serious people — Prime Intellect, Nous/Psyche, Together AI, CoreWeave — building the scaffolding for a world where intelligence becomes a commodity.
None of it matters if you can't turn the lights on.
There is a layer beneath compute that the industry has collectively decided to ignore — not because it isn't important, but because it's hard in a way that software people don't like. It doesn't yield to clever algorithms. It doesn't follow Moore's Law. It doesn't compress, parallelize, or shard.
Power. Electrical power. The raw, thermodynamic, physical substrate without which no GPU spins, no gradient descends, no token is generated.
You can buy 100,000 H100s tomorrow. You cannot plug them in.
This is not a prediction. This is the present. And every month the gap widens. What's emerging is the most consequential infrastructure crisis since the buildout of fiber-optic networks in the 1990s — except this time, the physics is harder, the timelines are longer, and the stakes are measured in whether artificial intelligence hits a ceiling imposed not by algorithms but by thermodynamics.
This pattern is older than electricity itself. The Dutch exhausted their peat bogs and pivoted to coal. The British stripped their forests and industrialized coal mining. The 20th century demanded mobility and pivoted from coal to oil. Every energy transition in history hit the same wall: demand outran supply, and the infrastructure to deliver the new fuel lagged by decades. We are in that lag right now.
McKinsey estimates $5.2 trillion in cumulative AI infrastructure capex through 2030. Goldman Sachs projects $720 billion in grid upgrades alone. The question isn't whether this problem matters. It's who builds the intelligence layer that solves it.
How Much Power Are We Actually Talking About
Let's stop being polite about this.
Global data center electricity consumption hit 415 TWh in 2024 — the entire electricity demand of France. The IEA's 2025 energy outlook projects this doubling to 945 TWh by 2030 — the total electricity consumption of Japan — with AI-accelerated servers growing 30% annually. AI-optimized servers alone will scale from 93 TWh (2025) to 432 TWh by 2030. A nearly 5x increase in five years. AI's share of total data center power: ~15% today, 35-50% by 2030. In the United States alone, data centers will consume 7.8-12% of national electricity by decade's end, up from 4% today. A Columbia University SIPA analysis projects U.S. AI LLM electricity demand alone could reach 14 GW by 2030 — a trajectory that mirrors Ireland, where data centers are on track to consume 32% of national power by 2026. McKinsey projects U.S. data center capacity will reach 80-90+ GW by 2030, with AI-related demand accounting for 156 GW of the 219 GW global total.
The Stanford HAI 2025 AI Index puts a finer point on it: training compute is doubling every 5 months. Not annually. Every five months. This is not speculation. This is hardware physics, compounding:
| GPU | TDP (Watts) | Year |
|---|---|---|
| NVIDIA A100 | 400W | 2020 |
| NVIDIA H100 | 700W | 2022 |
| NVIDIA B200 | 1,000-1,200W | 2024 |
| NVIDIA GB200 NVL72 (rack) | 132,000W | 2025 |
One GB200 NVL72 rack. 132 kilowatts. A traditional server rack pulls 5-10 kW. That's a 13-26x increase in power density in a single hardware generation. NVIDIA's own roadmap projects 1 MW per rack by 2030. One megawatt. Per rack. These are not data centers in any historical sense — they are industrial energy facilities that happen to run matrix multiplications.
 Signal Hill, California, 1926. A quiet residential neighborhood transformed into a forest of oil derricks almost overnight. Today, farmland across Virginia, Texas, and the Pacific Northwest is undergoing the same transformation — not for oil, but for compute. The pattern repeats: new demand, old infrastructure, landscapes remade. Source: Wikimedia Commons
Signal Hill, California, 1926. A quiet residential neighborhood transformed into a forest of oil derricks almost overnight. Today, farmland across Virginia, Texas, and the Pacific Northwest is undergoing the same transformation — not for oil, but for compute. The pattern repeats: new demand, old infrastructure, landscapes remade. Source: Wikimedia Commons
{kind=link}
And here's what the "training is the hard part" crowd keeps getting wrong: inference accounts for 70-90% of AI's total energy lifecycle. Every API call. Every chat completion. Every agent loop. Every tool-use chain. These are thermodynamic events — they scale linearly with usage, and usage is going vertical. GPT-4 consumed an estimated 50-62 GWh to train — enough to power San Francisco for three days. Training energy is growing roughly 40-48x per model generation. But cumulative inference cost over a model's deployment dwarfs training by orders of magnitude. As AI embeds into search, productivity, and enterprise applications, inference demand becomes the dominant term in the equation.
The per-query numbers look small in isolation. Jeff Dean noted that a median Gemini text prompt uses just 0.24 watt-hours — roughly 9 seconds of TV watching — with a 33x reduction in energy footprint from May 2024 to May 2025 through model, hardware, and clean energy optimizations. But efficiency per query is irrelevant when you're scaling to billions of queries per day. Andrew Ng has pointed out the asymmetry: inference capacity investment is justified because token generation demand from agents is compounding, while training infrastructure risks overinvestment if open models keep closing the gap. The Stanford HAI 2025 AI Index Report confirms the pattern — inference costs for GPT-3.5-level performance dropped 280-fold from 2022 to 2024, and hardware energy efficiency is improving ~40% annually. None of this slows aggregate demand. It accelerates adoption.
The industry is scaling demand on an exponential curve against supply infrastructure that moves at the speed of concrete and permitting.
The Queue Problem
Here is the entire crisis, compressed into five lines:
- Data center construction: 1-2 years
- Power plant construction: 2-10+ years
- Transmission line construction: 5-10+ years
- U.S. grid interconnection queue (average): 5 years
- PJM interconnection queue (largest U.S. grid operator): 8+ years
Read that again. The largest grid operator in the United States has an 8-year wait to connect new power. Europe is worse — 10+ years in parts of the continent.

There are 2,300 GW of generation and storage capacity sitting in U.S. interconnection queues right now. That is twice the entire installed power plant fleet of the United States. Of all projects that entered these queues between 2000 and 2019, only 13% reached commercial operation. Eighty-seven percent died waiting.
The grid has never moved fast. Edison's Pearl Street Station — the first commercial power plant in the United States — opened in 1882. Full rural electrification wasn't achieved until the 1950s. It took 70 years to wire a single country. We are now asking that same infrastructure to absorb an order-of-magnitude load increase in under a decade.
In Virginia — home to 13% of global data center capacity — $98 billion in projects are blocked or delayed because there is no power. PJM capacity auction prices spiked 833% in a single year, from $28.92 to $329.17 per MW-day, driven almost entirely by data center demand. Dominion Energy received interconnection requests equivalent to the electricity demand of 11.7 million homes. Microsoft's CFO warned capacity constraints would persist through mid-2026 — the company has been "tapping the brakes" on construction. Not for lack of capital. For lack of watts.
The response tells you everything: 46 data centers (56 GW combined) announced behind-the-meter power generation plans, with 90% announced in 2025 alone. When the richest companies on earth start building their own power plants, the grid has already failed them.
And the failure isn't abstract. In 2024, a single grid disturbance in Virginia caused 60 data centers to simultaneously switch to backup generators, dropping 1,500 MW off the grid — equivalent to the entire power demand of Boston. Gone. In seconds. Ireland now sends 21-22% of national electricity to data centers; Dublin paused new data center projects entirely. Carnegie Mellon projects an 8% average U.S. electricity bill increase by 2030 from data center demand, with 25%+ increases in the highest-demand markets. Communities near data center hubs are already reporting climbing utility bills. In 2025, 25 data center projects were canceled due to local resistance. In Prince William County, Virginia, residents halted a multi-billion-dollar campus and voted out the officials who supported it.
This is not a problem that's coming. It arrived. And it's radicalizing communities.
Distributed Compute Does Not Solve This. Bits vs. Joules.
There is a seductive argument floating around the AI infrastructure space: if we can distribute training across the world's idle GPUs, surely we can distribute the energy problem too.
No. And the people making this argument have confused bits with joules.
Electricity follows Kirchhoff's laws, not TCP/IP. You cannot route a megawatt from Tokyo to Texas. You cannot shard power across continents. You cannot apply DiLoCo to a transformer substation. Energy is fundamentally, irreducibly, stubbornly local — governed by physics (transmission losses scale with distance), by infrastructure (lines have finite capacity and take a decade to build), and by regulation (energy markets are among the most heavily regulated sectors in every jurisdiction on earth).
Distributed compute solutions — brilliant as they are — solve access to and cost of compute. They do not solve the energy constraint. They distribute it. Every GPU, wherever it sits in whatever heterogeneous swarm, requires power. Distributing compute to thousands of locations with varying grid reliability and capacity makes the energy orchestration problem exponentially harder, not easier.
Energy is the layer below compute. It is the substrate. You can buy GPUs, but you cannot deploy them without power. Solving distributed compute without solving distributed energy merely scatters the same unsolved problem across more geographies, more grid operators, and more regulatory jurisdictions.
And there's a deeper asymmetry the market has not priced in:
Compute efficiency improves. Energy efficiency hits thermodynamic walls. DeepSeek proved that algorithmic cleverness can dramatically reduce compute requirements for a given capability level. Good. But there is no DeepSeek for watts. Carnot efficiency doesn't yield to gradient descent. Every joule of useful computation generates waste heat that must be removed — and cooling is already the dominant energy overhead in high-density AI clusters. Google's fleet-wide PUE is 1.09. Microsoft's is 1.16. The industry average remains 1.56. That gap represents enormous optimization headroom, but the thermodynamic floor is immovable.
Energy infrastructure outlives compute infrastructure by an order of magnitude. GPU refresh cycle: 2-3 years. Power plant lifetime: 20-40 years. Transmission line: 50+ years. The energy decisions being made right now — or more accurately, not being made — will constrain AI's possibility frontier for decades. The world didn't switch from coal to oil because coal ran out. Oil had higher energy density and was easier to transport. But the infrastructure transition — pipelines, refineries, tanker fleets, filling stations — still took half a century. The physics of energy transitions is stubbornly slow regardless of how urgent the demand.
Regulatory complexity creates moats in energy that cannot exist in compute. Compute is being commoditized — it should be. But energy remains locally regulated and physically constrained. Every jurisdiction, every grid operator, every utility commission, every interconnection process is different. This is a feature for those who understand it, and a wall for those who don't.
Goldman Sachs, not exactly prone to hyperbole: "Lack of capital is not the most pressing bottleneck for AI progress — it's the power needed to fuel it."
If the United States fails to solve this, the consequence is not merely slower scaling — U.S. companies may be compelled to outsource AI development overseas to jurisdictions with more available power. France is already building exascale national compute clusters. The Middle East is funding sovereign AI campuses with cheap natural gas. The binding constraint reshapes geopolitics.
Who Is Actually Delivering Watts: 500 MW Against 220 GW of Demand
We mapped the actual state of energy solutions for AI infrastructure. No hype. No "by 2035" projections dressed up as present tense. Here is what is real, what is funded, what is unproven, and what is vapor.
Delivering Power Right Now
Bloom Energy: the standout. 1.5 GW of solid oxide fuel cells deployed across 1,200+ installations. Hundreds of MW specifically serving data centers — Oracle, Equinix, and others. Deployment speed unmatched: 50 MW in 90 days, 100 MW in 120 days, while grid connections take years. A $5 billion partnership with Brookfield for AI data centers and a 1 GW deal with AEP signal massive near-term scaling. Trade-off: runs primarily on natural gas. Amazon canceled their Bloom deal over precisely this concern.
Crusoe Energy: $10B+ valuation, $4.1B total funding. Originally pioneered a flare-gas-to-compute model (250+ MW deployed, 400+ modular data centers), then divested its entire flare gas and Bitcoin mining operations in March 2025 to become pure-play AI infrastructure. Now the lead developer for the flagship Stargate site — 1.2 GW in Abilene, Texas, backed by $15 billion in project financing. Phase 1 (200+ MW) operational. Revenue: $276M (2024) -> projected $998M (2025). Full buildout targets mid-2026.
Lancium: the energy orchestrator underneath Crusoe at Abilene. Handles land, grid interconnection, behind-the-meter renewables, power management through proprietary Smart Response software. $600M in debt financing secured. Developing multiple GW-scale campuses across Texas.
Amazon/Talen Energy: the only hyperscaler currently receiving nuclear power at scale — approximately 300 MW flowing from the Susquehanna plant through a 1,920 MW PPA extending to 2042.
Google's Fervo Project Red: 3.5 MW of geothermal since November 2023. Small, but real and generating.
Under Construction with Firm Financing
Microsoft/Constellation Three Mile Island restart: 835 MW by 2027 ($2.6B committed, 20-year PPA). Constellation also signed a 1,121 MW PPA with Meta at Clinton. Fervo Cape Station: 100 MW by 2026, 500 MW by 2028. Google/NextEra Duane Arnold nuclear restart: 615 MW by Q1 2029 ($1.6B+). Amazon/Talen expanded PPA: 1,920 MW ramping through 2032. Combined: 3-4 GW by 2029.
Technology Unproven: SMRs
Google/Kairos Power (500 MW, 2030-2035). Amazon/X-energy (320-960 MW, early 2030s). Meta nuclear procurement (1-4 GW, timeline uncertain). Oracle's 1 GW SMR data center (no technology even selected).
The uncomfortable truth that every press release about SMRs omits: no advanced small modular reactor has generated a single commercial kilowatt-hour in the United States or Europe. Not one. Oklo's first 15 MW reactor — late 2027 at the absolute earliest. Kairos Hermes 2 (50 MW) — not until 2030. NuScale has NRC design certification but canceled its first commercial project and has no operating reactor. The SMR opportunity is real on a decade-long timeline. It is not a solution to the current crisis.
Pure Vaporware
Microsoft's Helion fusion PPA. Google's Commonwealth Fusion deal. Amazon's aspirational 5 GW SMR target by 2039. No fusion plant has ever achieved sustained net energy gain for commercial power generation. These are press releases, not power plants.
The Gap
Actual non-grid clean energy flowing to AI data centers today: ~500 MW. Projected demand by 2030: 120-220 GW. That is a gap of two to three orders of magnitude. It is not closing. It is accelerating.
GPU Clusters Are Not Normal Grid Loads
This is where the technical problem becomes genuinely interesting, and where even sophisticated energy companies are walking into a buzzsaw.
AI workloads have power consumption profiles unlike anything the grid — or any behind-the-meter system — was designed for. During synchronous training, thousands of GPUs operate in lockstep. Their aggregate power consumption mirrors a single node's pattern rather than averaging out across the cluster. This is the opposite of what grid engineers expect from large loads.
The result: abrupt multi-megawatt transitions between idle and full power. Resonance effects that stress transformers and switchgear. Grid destabilization from sudden load swings that look, to a utility, like a fault event.
NVIDIA understood this deeply enough to build power management into the silicon with the GB300 NVL72:
Power capping — gradual ramp-up at workload start, not instantaneous. Electrolytic capacitor storage — onboard energy buffers that charge during low-demand phases and discharge during peaks. GPU burn mechanism — controlled power dissipation during abrupt workload termination to prevent sharp load drops that would destabilize upstream equipment. Combined, these reduce peak grid demand by up to 30%.
When the GPU manufacturer starts building grid-stabilization hardware into the chip, that should tell every energy company in the world: the customer you think you understand is not the customer you're serving.
Power quality specs for GPU clusters — +/-5% voltage regulation, <5% THD (IEEE 519-2014), 0.95-0.98 power factor — are table stakes. Meeting them with distributed, variable energy sources at 132 kW per rack, scaling to 1 MW, while matching the stochastic power profile of synchronized gradient computation — that is an unsolved engineering problem.
The storage requirements alone stratify by timescale. Seconds-to-minutes smoothing for GPU synchronization transients: electrolytic capacitors, supercapacitors. 2-4 hour peak shaving and arbitrage: lithium-ion LFP ($150-300/kWh, 90-95% round-trip efficiency). 8+ hour backup and overnight renewable bridging: flow batteries — vanadium redox or organic — with 20,000+ cycle life and no thermal runaway risk, critical when you're sitting next to a billion dollars of GPUs. Hithium has launched a purpose-built AIDC ESS combining 6.25 MWh LFP with 2.28 MWh sodium-ion specifically for AI data center power fluctuation profiles.
MIT researchers have emphasized that inference — not training — is the primary energy driver because generative AI is now embedded in daily applications used by hundreds of millions of people. Every search query, every code completion, every agent chain is a thermal event at the grid edge. The power profiles these workloads generate are unlike anything traditional energy infrastructure was designed to handle.
This requires a new kind of energy orchestration. One that thinks in tensors and training steps, not just megawatts and power factors.
The Technical Primitives Exist. Nobody Has Assembled Them.
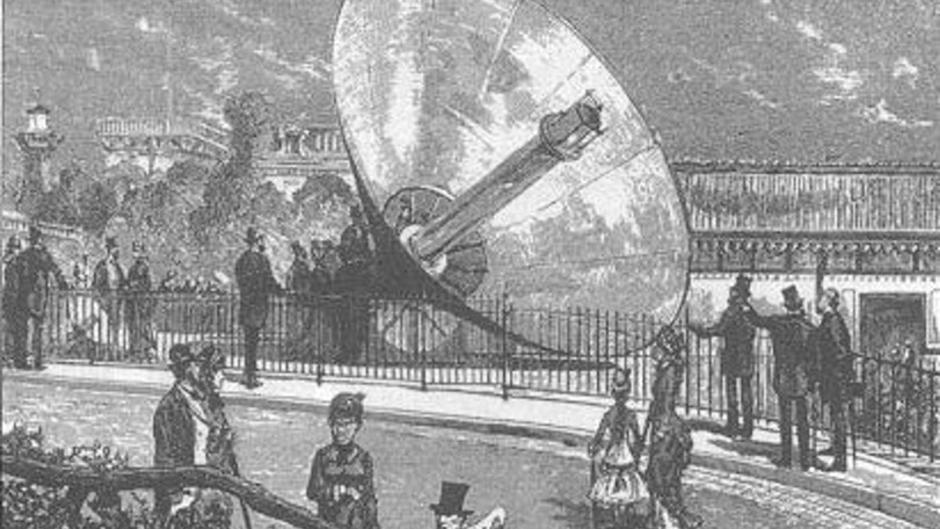 Augustin Mouchot's solar-powered steam engine at the 1878 Paris Universal Exhibition. The French government funded its development after coal shortages during the Franco-Prussian War exposed the danger of energy dependence. The technology worked. But cheap British coal flooded the market, and the project was shelved. The components existed — the system conditions didn't. Source: Wikimedia Commons
Augustin Mouchot's solar-powered steam engine at the 1878 Paris Universal Exhibition. The French government funded its development after coal shortages during the Franco-Prussian War exposed the danger of energy dependence. The technology worked. But cheap British coal flooded the market, and the project was shelved. The components existed — the system conditions didn't. Source: Wikimedia Commons
The pattern above should look familiar. In 1878, a working solar steam engine sat in the middle of Paris — proof that alternative energy generation was technically feasible. But there was no economic pressure to integrate it into a system. Cheap coal killed the urgency. Today, every component technology for AI energy orchestration already exists. And this time, the demand is not hypothetical — it is 220 GW and growing.
Here's what makes this a platform opportunity rather than a pure research problem: almost every component technology required already exists. What doesn't exist is the integrated system.
DER aggregation has a mature control stack. At the device level, IEEE 2030.5 provides granular two-way control of inverters, batteries, and distributed generators. At the aggregator level, OpenADR 2.0b handles demand response signals and event-based load shifting. At the utility/grid level, IEC 61850 manages substation automation. The DOE/NREL FAST-DERMS reference architecture employs federated control — DERs at each substation optimized locally, then aggregated at the distribution system operator level for wholesale market participation. The protocol stack is there. The AI-workload-aware intelligence on top of it is not.
Carbon-aware workload scheduling is production-ready — at Google scale. Google's Carbon-Intelligent Computing System (CICS) operates across 20+ data centers on 4 continents, managing over 15.5 TWh of electricity. It uses Virtual Capacity Curves to impose hourly limits on temporally flexible workloads, shifting computation to greener hours and regions. SLO: daily compute capacity violations <=1 day per month. Microsoft's open-source Carbon-Aware SDK integrates with WattTime's API for similar time/location shifting. Cloudflare's "Green Compute" routes inference to lower-carbon backends. The practical limitation: multi-week distributed training runs across thousands of GPUs cannot be easily paused or migrated. Carbon-aware scheduling works for batch processing and inference. Not for frontier training.
AI-driven energy optimization is the most powerful tool available. Google DeepMind's data center cooling optimization achieved a 40% reduction in cooling energy and a 15% improvement in overall PUE — producing the lowest PUE the facility had ever recorded. Ensemble of deep neural networks. Thousands of sensor data points. Predictions every 5 minutes. Independent replications: 9-21% savings. Hyperscaler PUEs: Google 1.09, Microsoft 1.16. Industry average: 1.56. That gap — between best-in-class and average — is an enormous optimization opportunity, and it widens as AI rack densities make cooling the dominant energy overhead.
Every primitive exists. Carbon-aware scheduling. DER aggregation. AI-optimized cooling. Power quality management. Battery buffering at multiple timescales. Grid capacity intelligence.
Nobody has assembled them into a single orchestration layer purpose-built for the unique power signatures of GPU clusters. That's the gap.
The Market Is Measured in Trillions. The Capital Is Here. The Watts Are Not.
Global AI data center spending: $236B (2025) -> $934B (2030), 31.6% CAGR. Energy-specific TAM at $50-100/MWh commercial rates applied to projected consumption: $50-100 billion annually by 2030 for electricity alone — several hundred billion including generation, transmission, storage, and cooling infrastructure.
Capital is flooding in at unprecedented scale. As Andrew Ng observed, Meta alone is spending $66-72 billion in 2025 capex, much of it on AI data centers — hardware costs so dominate that it justifies paying model builders whatever they ask, because GPUs and power dwarf labor by orders of magnitude. $61 billion+ in global data center deals closed in 2025, exceeding all of 2024. KKR: $50B joint venture for AI data centers and power infrastructure. Blackstone: tens of billions across QTS ($6.7B), AirTrunk ($16.1B), Digital Realty ($7B JV), Lancium ($500M). BlackRock/GIP + Microsoft + MGX: multi-billion Global AI Infrastructure Partnership. Project Stargate: $500B announced (execution slower than expected). Startup valuations: Crusoe $10B+ ($4.1B raised), CoreWeave billions in debt facilities ($14B Meta contract), X-energy $700M Series D, Fervo $462M Series E (Google equity), Base Power $1B Series C.
And this is not only a U.S. phenomenon. Yann LeCun has highlighted France's national GPU clusters — Jean Zay (126 petaflops operational since 2019) and Alice Recoque (targeting 1 exaflop in 2026) — as examples of government-backed AI compute infrastructure that the U.S. lacks at the federal level. Every major economy is racing to build sovereign AI capacity. All of them need power.
The capital is here. The GPUs are here. The models are here. The algorithms are here.
The power is not here. And the software that intelligently orchestrates distributed power for AI workloads — purpose-built for the stochastic energy signatures of synchronized gradient computation — that doesn't exist yet.

The Risks Are Real. What Stands in the Way?
We are not naive about what stands in the way.
Hyperscaler competition. Google acquired Intersect Power for $4.75 billion. Microsoft signed a 10.5 GW deal with Brookfield. Every major tech company now has internal energy teams verticalizing aggressively. These companies have more capital than God. What they don't have is the ability to move fast across fragmented regulatory jurisdictions, or the incentive to build horizontal platforms that serve competitors.
Regulatory risk. A single FERC ruling — like the Susquehanna behind-the-meter rejection — can obliterate a business model overnight. Navigating 50 state PUCs is operationally brutal. This is also precisely where the moat forms: the companies that master this labyrinth create advantages that cannot be replicated by throwing engineers at the problem.
Efficiency gains could shrink the TAM. DeepSeek proved algorithmic improvements can dramatically reduce compute requirements. Jeff Dean demonstrated a 33x reduction in energy per Gemini inference query over a single year — from model optimization, hardware improvements, and clean energy sourcing combined. He also critiqued a widely cited 2019 paper on AI training emissions, showing its estimates were overstated by factors of 88x to 118,000x depending on hardware efficiency assumptions — a reminder that the discourse around AI energy often operates on bad data. This is a real risk — every efficiency gain reduces energy demand at the margin. Our view: efficiency gains create new demand by making AI economically viable in more applications. The history of computing shows this clearly — efficiency never reduces total energy consumption; it accelerates adoption. A February 2026 Nature study analyzing 52 countries found that AI investments actually boost energy security by 1.68-8.39%, suggesting the relationship between AI and energy is not purely extractive — AI deployed into energy systems improves the systems themselves.
Community opposition. 25 data center projects canceled in 2025. Prince William County residents halted a multi-billion-dollar campus and voted out supporting officials. The social license to operate is not guaranteed.
We see these risks. We also see 500 MW against 220 GW of demand. The gap dwarfs the risks.
The Moat That Matters
The "Psyche for energy" metaphor is directionally right but physically wrong. Energy cannot be transmitted like data. You cannot route megawatts across a peer-to-peer network. PowerLedger — the most prominent blockchain energy trading platform — has facilitated 1.67 GWh of trading in its entire history. That's negligible at AI scale. Tokenized energy trading has remained pilot-stage for a decade.
The realistic version is not fully decentralized energy. It is intelligently coordinated distributed energy operating within existing regulatory frameworks, using software to make fragmented infrastructure behave like a unified system.
And the strongest moat in this space is not technology. It's not a patent. It's not a novel battery chemistry.
It is regulatory expertise fused with energy market access fused with proprietary grid intelligence.
Knowing FERC. Knowing fifty state PUCs. Knowing which interconnection queues move and which die. Knowing wholesale market mechanics well enough to arbitrage across them in real-time. Knowing grid topology well enough to identify available capacity that utilities themselves don't know they have.
Then abstracting all of it into a platform that a data center operator can consume as a service.
The closest existing analogies are Voltus (8.1 GW under management, demand response orchestration) and Lancium's Smart Response (energy optimization across grid, renewables, and storage). Neither is purpose-built for AI workload profiles. Neither fuses supply aggregation with demand intelligence. Neither solves the full problem. GridCARE ($13.5M raised) uses generative AI to detect available grid capacity, claiming 6-12 month time-to-power. Google-backed Tapestry is developing AI for faster grid connections. These are right ideas. They need to be welded into a single coherent orchestration layer.
Compute is being commoditized. Energy cannot be. It is local, physical, regulated, and slow to build. The exact properties that make energy hard are what make the intelligence layer on top of it defensible.
Why This Timing. Why Now.
The demand is not theoretical. ~500 MW against 120-220 GW projected. Not a gap — a chasm measured in orders of magnitude.
The regulatory environment is splitting. The U.S. is deregulating and sprinting to build. Europe is tightening efficiency mandates. Both create massive demand for intelligent energy management — the former because new supply needs orchestration, the latter because existing supply needs optimization.
The hardware layer is adapting to distributed power. NVIDIA's GB300 power-smoothing — capacitor buffering, power capping, controlled burn — is the silicon manufacturer telling the world that frontier AI will run on coordinated distributed energy. This was not technically feasible two years ago. It is now.
The incumbents are not positioned. Utilities think in 20-year planning cycles. Energy tech startups think in generic load profiles. Neither understands that a synchronized 10,000-GPU training run has a power signature that looks like nothing they've ever managed. The company that understands both energy systems and GPU workload dynamics occupies a space that currently does not exist.
The startup wedge is narrow but powerful. The winning strategy is not to build power plants — a 250 MW AI data center costs ~$12B all-in, and even Crusoe needed $4.1B equity + $15B project financing. That's infrastructure fund territory. The venture-scale prize is the intelligence layer: software-defined energy orchestration that sells compute-ready megawatts rather than raw electricity, embedding regulatory expertise, grid intelligence, and reliability guarantees that no existing platform provides. Crusoe's trajectory — VC for the company, project finance for the data centers, $10B+ valuation in under 7 years — validates the hybrid model.
The Declaration
The distributed compute revolution assumed energy would follow. It hasn't.
The grid is not keeping pace. The interconnection queues are not shrinking. The megawatts are not materializing. The smartest infrastructure builders in AI are spending hundreds of billions on GPUs they cannot power and data centers they cannot energize. Communities are revolting. Utilities are overwhelmed. And the gap — 500 MW of non-grid clean energy against 220 GW of projected demand — is widening, not closing.
Civilizations have faced this before. Peat. Coal. Oil. Electrification. Every transition reshaped landscapes, economies, and power structures. None happened without someone solving the supply problem first. This is the next one — and it is moving faster than any that came before it.
We are building the operating system for AI energy infrastructure. Not a power plant. Not a marketplace. Not a token. The intelligence layer that makes fragmented, heterogeneous, locally-regulated energy infrastructure behave as a single, reliable, compute-ready power system — purpose-built for the unique thermodynamic and electrical demands of GPU clusters at scale.
Energy is AI's binding constraint. We intend to unbind it.
Matrix is an AI infrastructure lab building at the intersection of energy systems and intelligent compute. If you think about power profiles, grid topology, DERMS architectures, or workload-aware energy optimization — we should talk.